Frequently asked questions about the Dataset Register by developers of heritage software
Why are machine-readable dataset descriptions important?
In order for machines to understand the dataset descriptions, it is important that it is not only readable by humans, but also by the machine. Standards like schema.org/Dataset help to capture the semantics of the dataset descriptions. If rich information is provided, findability improves.
What information does a dataset description contain?
The information that is required and recommended - based on schema.org/Dataset - is described in a requirements document.
The image below indicates the layering of dataset descriptions:

How should dataset descriptions be published?
In terms of content, the dataset description must comply with a standard such as schema.org/Dataset (and later DCAT). In terms of display, also called serialization, there are several possibilities:
- included in an HTML as microdata or RDFa;
- as <script type="application/ld+json"> block containing JSON-LD an HTML page (inserted on the server side or injected via Javascript on the client side);
- as a separate RDF resource.
Most (automated) users expect the dataset description to be "embedded" in the HTML page. Spiders from search engines like Google do not track linked JSON-LD files. Also, Javascript-injected JSON-LD goes undetected by most spiders. There are more serializations of RDF, such as RDF/XML and Turtle. Spiders from search engines like Google only support microdata, RDFa and JSON-LD (the latter form is recommended by Google). Because findability is an important aspect, the use of inline JSON-LD is recommended. However, this does not affect the fact that dataset descriptions are also published in other serialization formats or via a separate resource (based on content negotiation).
The Dataset Register also supports data catalogs. This set of datasets provides information about all available datasets of an organization in one go.
What functions does the Dataset Register offer?
In addition to the website, the Dataset Register offers two access points: a REST API and a SPARL endpoint.
How can a dataset be registered with the Datasetregister?
Via the REST API, a URL can be submitted of a page where a dataset description is published, a direct URL of an RDF file with dataset description or a URL of a data catalog.
Via this website you can submit a URL of a dataset description or data catalog via the browser, using the REST API.
Can anyone add a dataset description to the Datasets Register?
If a domain name of a heritage institution or supplier is missing, please contact us.
How can a dataset description be checked?
Via the REST API, the dataset description of a dataset description can be checked against the Requirements for Datasets.
You can also check the dataset description using the more general Schema Markup Validator. Enter here the URL of the (online) page that contains the dataset description or paste a code snippet to run the test.
How does the Dataset Register work, technically?
The Dataset Register aims to become a pointer to datasets. To do this, the Dataset Register crawls the URLs of logged-in pages with dataset descriptions.
The dataset descriptions are validated and stored in a triplestore after conversion.
The design below shows the high-level components:
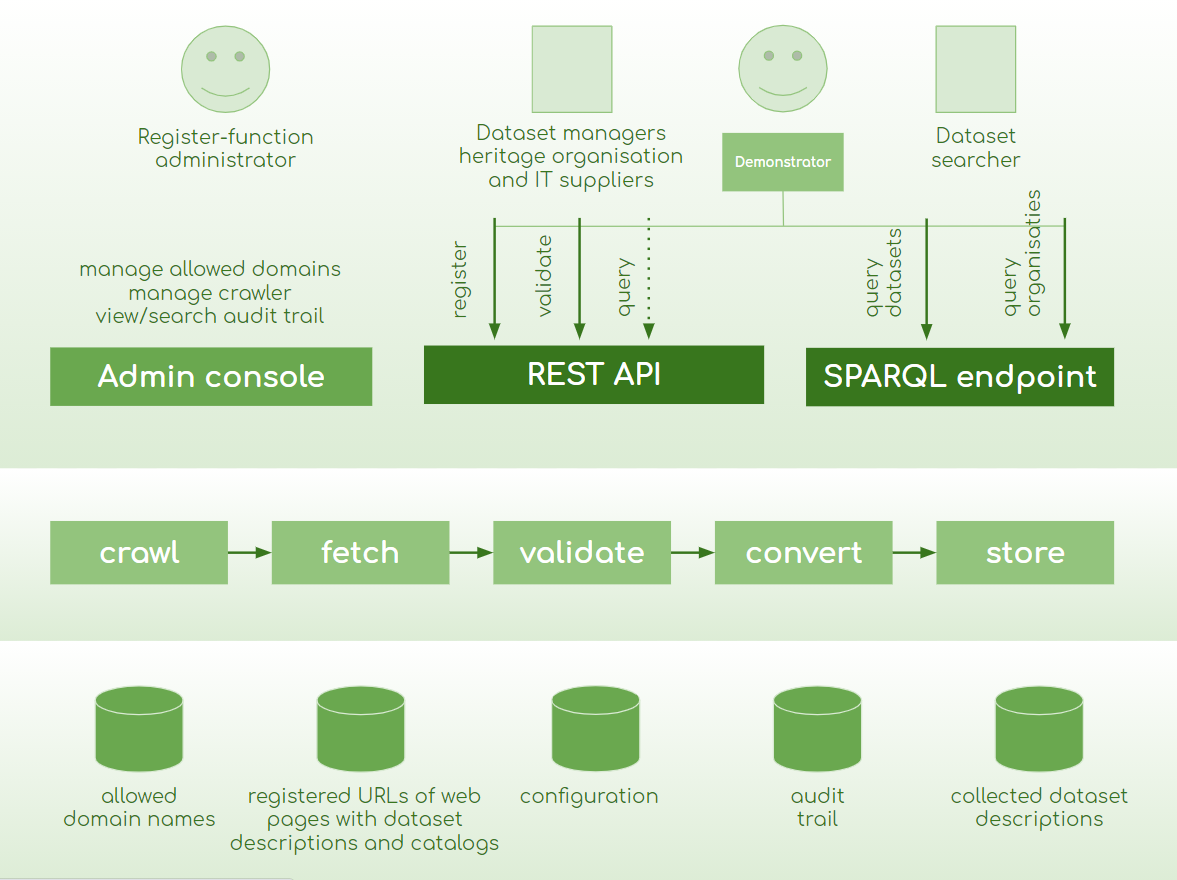
How can I try out the Dataset Register?
You can submit and search dataset descriptions via this website.
How can I access the Dataset Register API?
The URL of the Datasetregister API is https://datasetregister.netwerkdigitaalerfgoed.nl/api/
In the description of the API you will find information about the endpoint.
How can I use the Dataset Register from my collection management system?
The use of the API is open to all heritage institutions and their suppliers.
Who creates and manages the Dataset Register?
The Dataset Register was created by the collaborating heritage institutions in the Network Digital Heritage and is managed and maintained by the National Archives. The National Archives is responsible for the operation and availability of the Dataset Register.
Can I already use the Dataset Register?
Yes, of course! The Dataset Register is still being developed and filled in even further, but can already be used. We'd love to hear what you think. For example: are the search options sufficient? Is the API usable?
If you want to go a step further, you can implement the Dataset Register in your collection management system so that collection managers can get started with it. We are happy to support you with this.
Are you getting started?
If you are going to start publishing dataset descriptions and the API on the Dataset Register, let us know so that we can keep you informed of developments, updates and availability.
Do you want to know more?
If you have any questions and/or comments about the functioning of the Dataset Register, please contact tech@netwerkdigitaalerfgoed.nl.