Veelgestelde vragen voor ontwikkelaars van erfgoedsoftware
Waarom zijn machine-leesbare datasetbeschrijvingen belangrijk?
Om machines de datasetbeschrijvingen te laten begrijpen is het van belang dat deze niet alleen leesbaar is voor de mens, maar ook voor de machine. Standaarden als schema.org/Dataset helpen om de semantiek van de datasetbeschrijvingen vast te leggen. Als er rijke informatie worden geboden verbeterd de vindbaarheid.
Welke informatie bevat een datasetbeschrijving?
De informatie die verplicht en aanbevolen is - op basis van schema.org/Dataset - staat beschreven in een requirements document.
Onderstaande afbeelding geeft de gelaagdheid aan van datasetbeschrijvingen:

Op welke wijze dienen datasetbeschrijvingen gepubliceerd te worden?
Inhoudelijk dient de dataset beschrijving te voldoen aan een standaard als schema.org/Dataset (en later DCAT). Qua weergave, ook wel serialisatie genoemd, zijn er verschillende mogelijkheden:
- opgenomen in een HTML als microdata of RDFa;
- als <script type="application/ld+json"> blok met JSON-LD in een HTML pagina (aan serverkant ingevoegd of via Javascript aan client-zijde geïnjecteerd);
- als los RDF resource.
De meeste (geautomatiseerde) gebruiker verwachten de datasetbeschrijving "ge-embed" in de HTML painga. Spiders van zoekmachines zoals Google volgen gelinkte JSON-LD bestanden niet. Ook, via Javascript geïnjecteerde JSON-LD wordt door de meeste spiders niet opgemerkt. Er zijn meer serialisaties van RDF, zoals RDF/XML en Turtle. Spiders van zoekmachines als Google ondersteunen alleen microdata, RDFa en JSON-LD (deze laatste vorm wordt door Google geadviseerd). Omdat vindbaarheid een belangrijk aspect is wordt het gebruik van inline JSON-LD geadviseerd. Echter, dit laat onverlet dat dataset beschrijvingen ook in andere serialisatieformaten of via een aparte resource (op basis van content negotiation) worden gepubliceerd.
Het Datasetregister ondersteunt ook datacatalogs. Deze set van datasets geeft in één keer informatie over alle beschikbare datasets van een organisatie.
Welke functies biedt het Datasetregister?
Het Datasetregister biedt, naast website, een tweetal toegangen: een REST API en een SPARL endpoint.
Hoe kan een dataset aangemeld worden bij het Datasetregister?
Via de REST API kan een URL worden aangemeld van een pagina waar een datasetbeschrijving wordt gepubliceerd, een directe URL van een RDF bestand met datasetbeschrijving of een URL van een datacatalog.
Via deze website kun je via de browser een URL van een datasetbechrijving of datacatalogus aanmelden, hierbij wordt er gebruik gemaakt van de REST API.
Kan iedereen een datasetbeschrijving toevoegen aan het Datasetregister?
Het aanmelden van datasets via de REST API werkt op basis van een lijst van toegestane domeinen. Datasetbechrijvingen (en datacatalogi) die afkomstig zijn van domeinen op deze lijst worden toegevoegd.
Ontbreekt er een domeinnaam van een erfgoedinstelling of leverancier, neem dan contact op.
Hoe kan een datasetbeschrijving gecontroleerd worden?
Via de REST API kan de datasetbeschrijving van een datasetbeschrijving worden gecontroleerd op de Requirements for Datasets.
Je kunt de datasetbeschrijving ook controleren met behulp van de algemenere Schema Markup Validator. Geef hier de URL op van de (online) pagina waarin de datasetbeschrijving is opgenomen of plak een codefragment om de test uit te voeren.
Hoe werkt het Datasetregister, technisch?
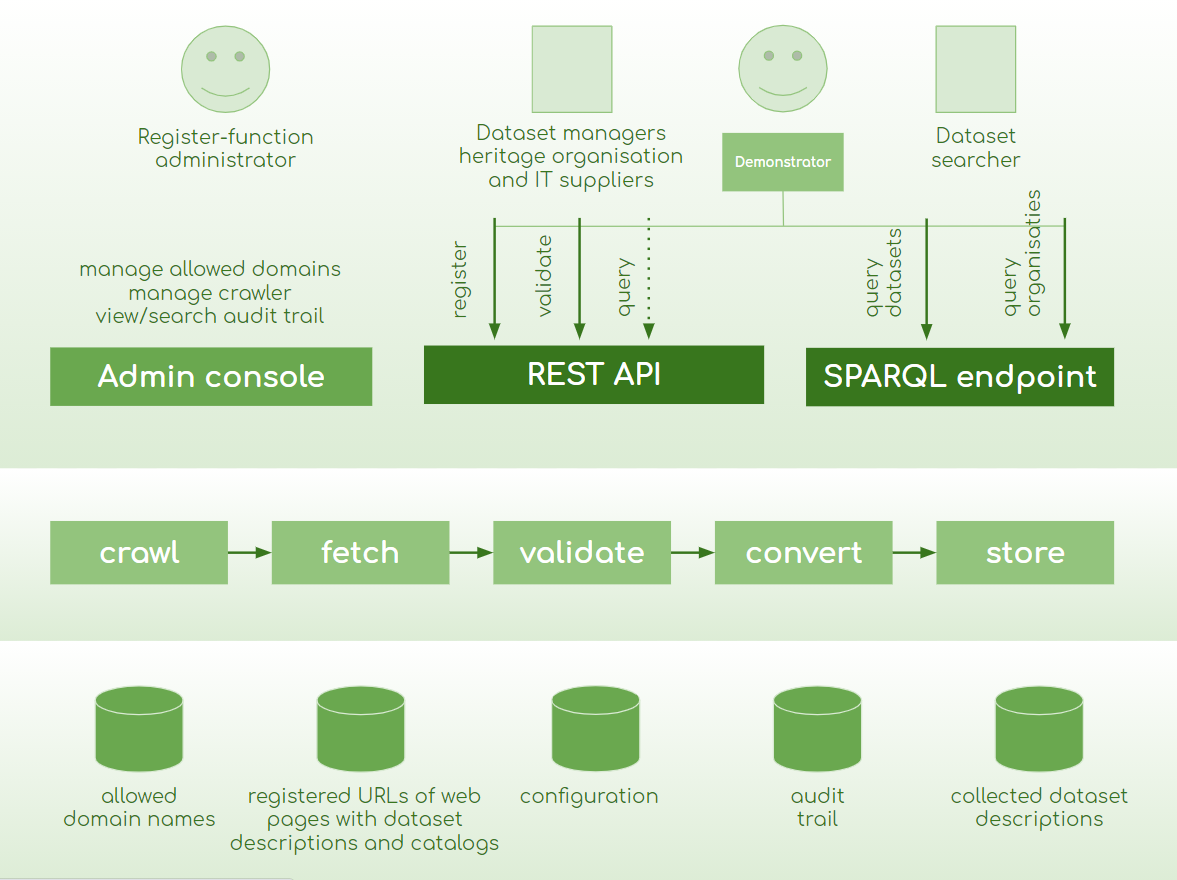
Het Datasetregister beoogt een verwijzer naar datasets te worden. Hiertoe crawlt het Datasetregister de URL's van aangemelde pagina's met datasetbeschrijvingen.
De datasetbeschrijvingen worden gecontroleered en na conversie opgeslagen in een triplestore.
Onderstaand ontwerp toont de high-level componenten:
Hoe kan ik het Datasetregister uitproberen?
Via deze website kun je datasetbeschrijvingen aanmelden en doorzoeken.
Hoe kan ik de API van het Datasetregister aanspreken?
De URL van de Datasetregister API is https://datasetregister.netwerkdigitaalerfgoed.nl/api/
In de beschrijving van de API vind je informatie over het endpoint.
Hoe kan ik vanuit mijn collectiebeheersysteem gebruikmaken van het Datasetregister?
Het gebruik van de API staat open voor alle erfgoedinstellingen en hun leveranciers.
Wie maakt en beheert het Datasetregister?
Het Datasetregister is gemaakt door de samenwerkende erfgoedinstellingen in het Netwerk Digitaal Erfgoed en wordt beheerd en onderhouden door het Nationaal Archief. Het Nationaal Archief staat in voor de werking en beschikbaarheid van het Datasetregister.
Wat is de status van het Datasetregister?
Het Datasetregister is klaar om verder gevuld te worden. De requirements, API en deze website zijn stabiel en worden op basis van feedback van gebruikers en leveranciers verfijnd.
Kan ik het Datasetregister nu al gebruiken?
Jazeker! Het Datasetregister wordt nog doorontwikkeld en nog verder gevuld, maar nu al te gebruiken. We horen dan ook graag wat je ervan vindt. Bijvoorbeeld: zijn de zoekmogelijkheden toereikend? Is de API bruikbaar?
Als je een stap verder wilt gaan, dan kun je het Datasetregister in je collectiebeheersysteem implementeren zodat collectiebeheerders ermee aan de slag kunnen. Wij ondersteunen je hier graag bij.
Ga je aan de slag?
Ga je aan de slag met het publiceren van datasetbeschrijvingen en de API op het Datasetregister, laat het weten, zodat we je op de hoogte kunnen houden van ontwikkelingen, updates en beschikbaarheid.
Meer weten?
Heb je vragen en/of opmerkingen over de werking van het Datasetregister neem dan contact op met tech@netwerkdigitaalerfgoed.nl.